运维
镜像仓库方案
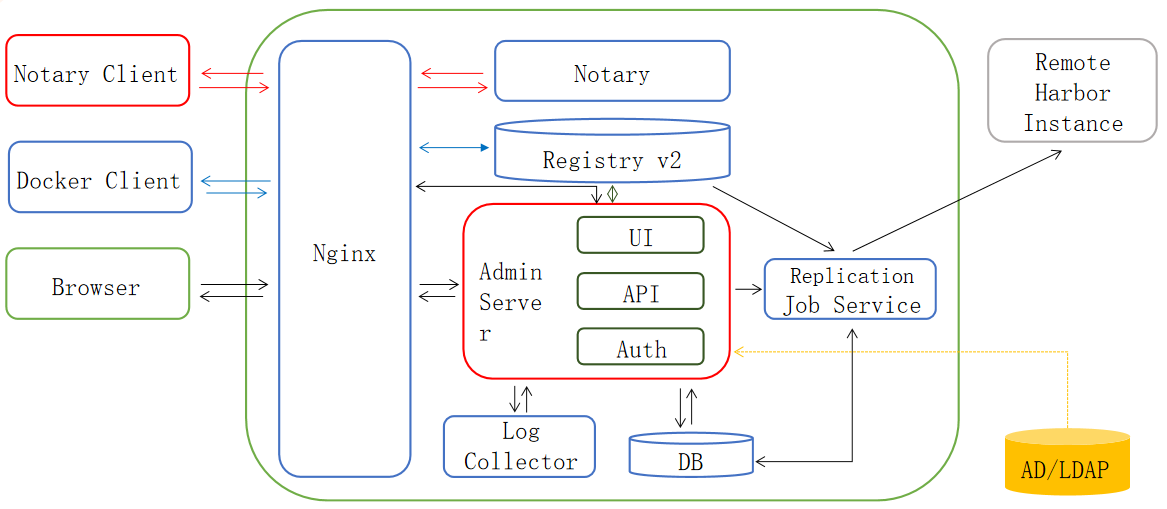
Harbor
介绍说明
Harbor 的目标是帮助用户迅速搭建一个企业级的 Docker registry 服务。它以 Docker 公司开源的 registry 为基础,额外提供了如下功能:
- 基于角色的访问控制(
RoleBased Access Control) - 基于策略的镜像复制(
Policy based image replication) - 镜像的漏洞扫描(
Vulnerability Scanning) AD/LDAP集成(LDAP/AD support)- 镜像的删除和空间清理(
Image deletion&garbage collection) - 友好的管理UI(
Graphical user portal) - 审计日志(
Audit logging) RESTful API- 部署简单(
Easy deployment)
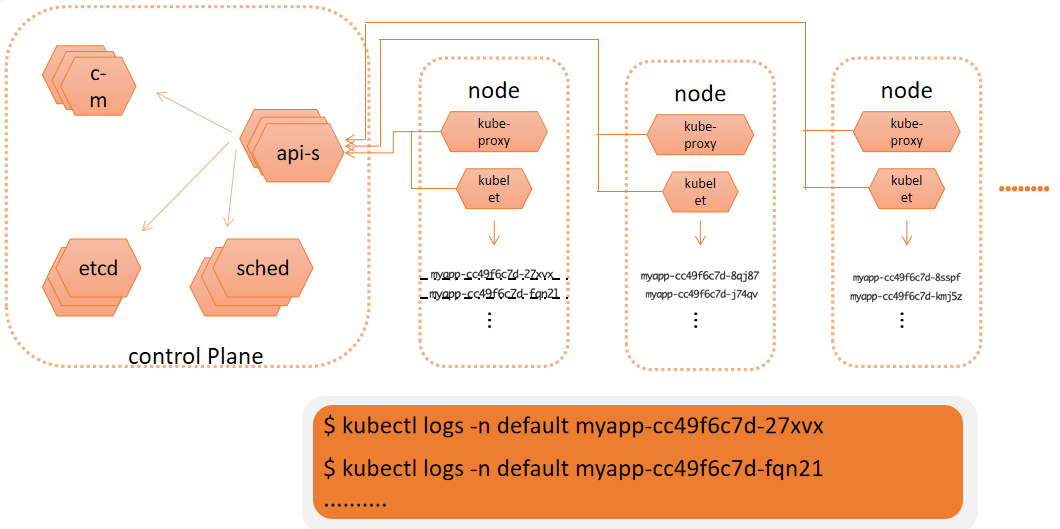
日志方案
每一类日志都去 kubectl logs 吗
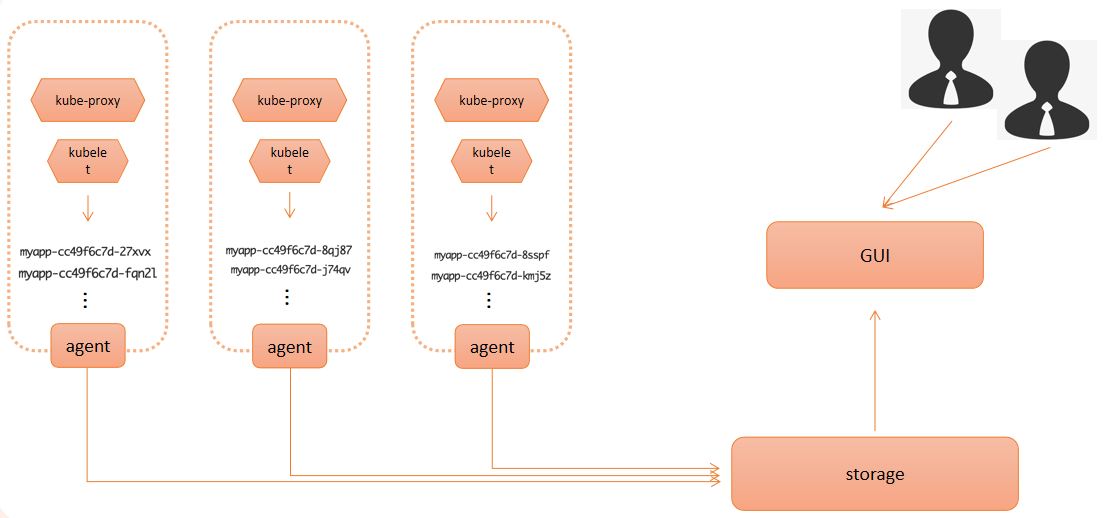
应该有的架构模式
EFK
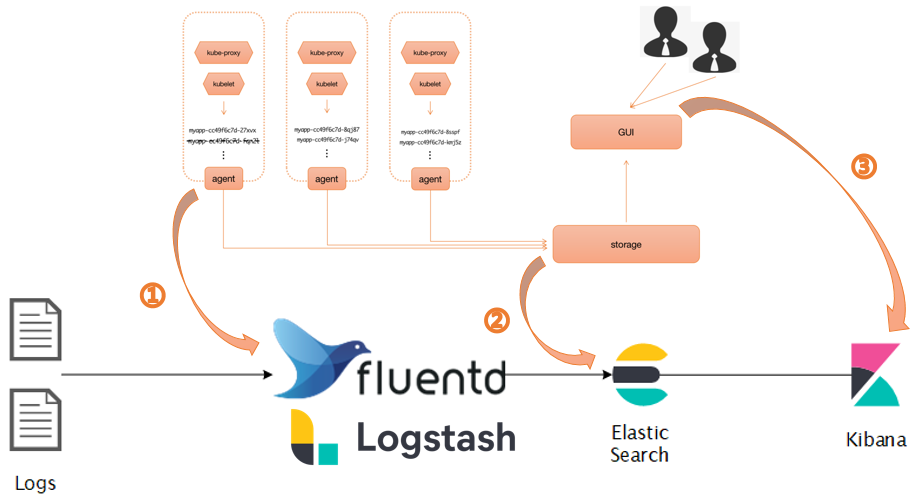
- 优势
- 功能完善
- 丰富的案例
- 劣势
- 资源消耗量大
- 灵活性差
LOKI
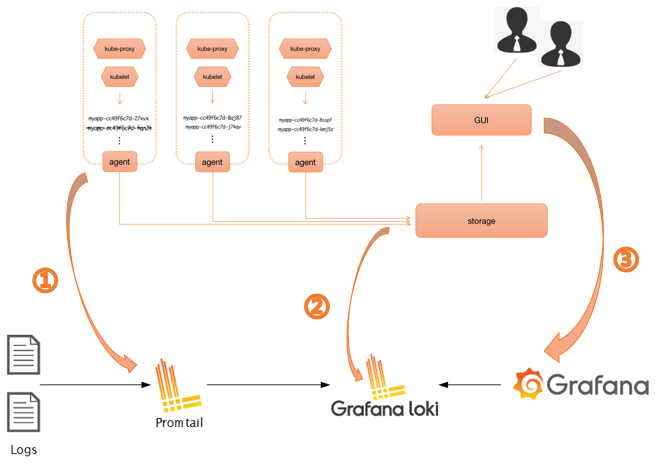
- 优势
- 资源消耗低
- 灵活性强-云原生
- 搜索速度快
- 劣势
- 案例相对较少
详细对比
- 存储方式:
Loki使用类似于散列表的内存数据结构,不需要进行索引,查询速度快;ELK和EFK使用Elasticsearch进行索引,查询速度可能比较慢。 - 数据收集和处理:
Loki使用Promtail进行数据收集和处理,EFK使用Fluentd进行数据收集和处理,ELK使用Logstash进行数据收集和处理,Fluentd相对于Logstash更轻量级,拥有更好的可扩展性;Logstash可以处理大量数据源,但可能需要更多的资源;Promtail是为Loki设计的,它的性能通常会优于Logstash,特别是在大规模日志收集场景下。Promtail可以有效地处理大量的日志数据,并且具有良好的水平扩展性。 - 扩展性:
ELK和EFK具有广泛的扩展性和适应性,可以对多种数据源进行处理;Loki的扩展性相对较弱。 - 学习曲线:
ELK和EFK相对于Loki具有更陡峭的学习曲线,因为它们具有更多的组件和功能。 - 可视化工具:
ELK和EFK使用Kibana进行数据可视化,Kibana提供了丰富的图表、表格和仪表盘等可视化工具;Loki使用Grafana进行数据可视化,Grafana也是一个强大的可视化工具,但它可能需要更多的配置和调整。
LOKI
Loki 是 Grafana Labs 团队最新的开源项目,是一个水平可扩展,高可用性,多租户的日志聚合系统。Like Prometheus, but for logs
与其他日志聚合系统相比,Loki 具有下面的一些特性:
- 不对日志进行全文索引。通过存储压缩非结构化日志和仅索引元数据,
Loki操作起来会更简单,更省成本。(LogQL) - 通过使用与
Prometheus相同的标签记录流对日志进行索引和分组,这使得日志的扩展和操作效率更高。 - 特别适合储存
Kubernetes Pod日志;诸如Pod标签之类的元数据会被自动删除和编入索引。 - 受
Grafana原生支持。
组成

components
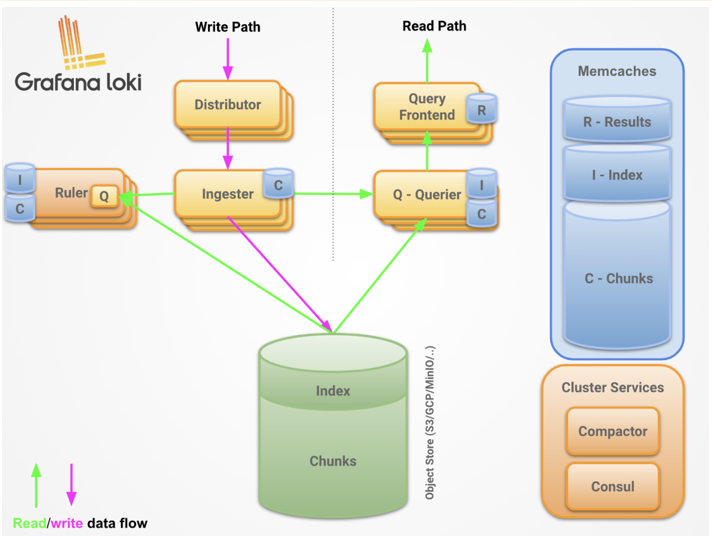
Distributor:- 用来将容器日志发送到
Loki或者Grafana服务上的日志收集工具
- 用来将容器日志发送到
Ingester:- 摄取服务负责在写入路径上将日志数据写入长期存储后端(
DynamoDB、S3、Cassandra等),并在读取路径上返回内存中查询的日志数据。 - 如果写入被
3个摄取器中的2个确认,我们可以容忍一个摄取器丢失,但不能容忍两个,因为这会导致数据丢失。 Loki默认配置为接受无序写入。
- 摄取服务负责在写入路径上将日志数据写入长期存储后端(
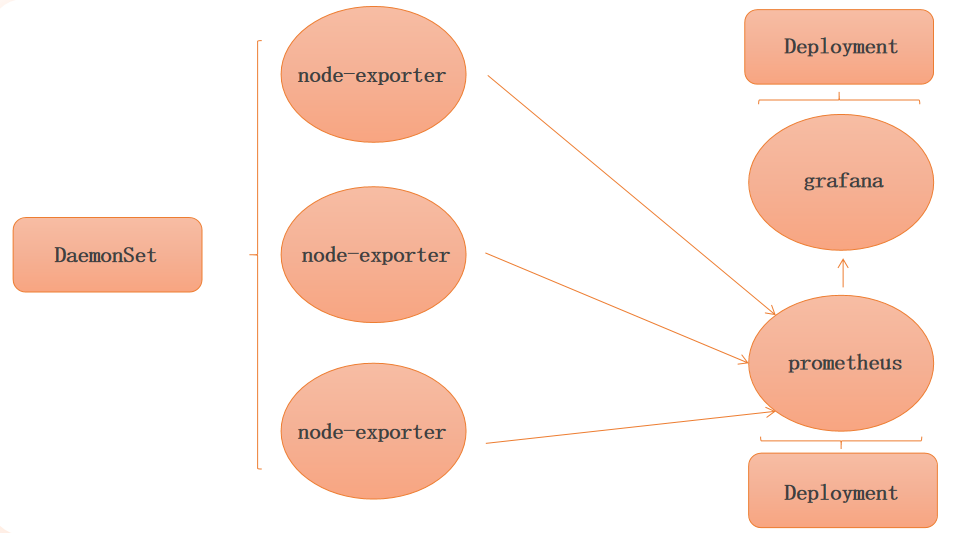
资源监控方案
Prometheus


固定 IP 地址至 pod
固定 IP 地址至 pod
apiVersion: v1
kind: Pod
metadata:
labels:
app: myapp
annotations:
"cni.projectcalico.org/ipAddrs": "[\"10.244.140.67\"]"
name: myapp-ip
namespace: default
spec:
containers:
- image: wangyanglinux/myapp:v1.0
imagePullPolicy: IfNotPresent
name: myapp
在使用过程中可能会遇到 IP 没有释放等问题导致 pod 启动失败,导致这种原因可能是 pod 被删除后,使用的 IP 地址未被释放,所以需要使用以下命令对地址池的 IP 进行释放,才能够被 pod 重新使用
$ calicoctl ipam release --ip 10.244.140.67
NetworkPolicy
网络策略
如果你希望在 IP 地址或端口层面(OSI 第 3 层或第 4 层)控制网络流量,则你可以考虑为集群中特定应用使用 Kubernetes 网络策略( NetworkPolicy )
Pod是通过如下三个标识符的组合来辩识是否可以通讯:- 其他被允许的
Pods(例外:Pod无法阻塞对自身的访问) - 被允许的名字空间
IP组块(例外:与Pod运行所在的节点的通信总是被允许的,无论Pod或节点的IP地址)
- 其他被允许的
网络策略通过 网络插件 来实现。要使用网络策略,你必须使用支持 NetworkPolicy 的网络解决方案。创建一个 NetworkPolicy 资源对象而没有控制器来使它生效的话,是没有任何作用的
隔离默认策略
- 出口的隔离
- 默认情况下,一个
Pod的出口是非隔离的,即所有外向连接都是被允许的
- 默认情况下,一个
- 入口的隔离
- 默认情况下,一个
Pod对入口是非隔离的,即所有入站连接都是被允许的
- 默认情况下,一个
特别说明
网络策略是相加的,所以不会产生冲突。如果策略适用于 Pod 某一特定方向的流量,Pod 在对应方向所允许的连接是适用的网络策略所允许的集合。因此,评估的顺序不影响策略的结果。
要允许从源 Pod 到目的 Pod 的连接,源 Pod 的出口策略和目的 Pod 的入口策略都需要允许连接。如果任何一方不允许连接,建立连接将会失败。
NetworkPolicy 资源
- 基本语法
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
podSelector:
matchLabels: # 空的 `podSelector` 选择名字空间下的所有 Pod
role: db
policyTypes: # NetworkPolicy 未指定 `policyTypes` 则默认情况下始终设置 `Ingress`
- Ingress
- Egress
ingress:
- from:
- ipBlock:
cidr: 172.17.0.0/16
except:
- 172.17.1.0/24
- namespaceSelector:
matchLabels:
project: myproject
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: TCP
port: 6379
egress:
- to:
- ipBlock:
cidr: 10.0.0.0/24
ports:
- protocol: TCP
port: 5978
- 选择器 - to 和 from 的行为
- 可以在
ingress的from部分或egress的to部分中指定四种选择器:-
podSelector
-
namespaceSelector
-
namespaceSelector 和 podSelector
-
...
ingress:
- from:
- namespaceSelector:
matchLabels:
user: alice
podSelector:
matchLabels:
role: client
...
-
-
ipBlock
-
- 默认策略
默认情况下,如果名字空间中不存在任何策略,则所有进出该名字空间中 Pod 的流量都被允许。 以下示例使你可以更改该名字空间中的默认行为
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-ingress
spec:
podSelector: {}
policyTypes:
- Ingress
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all-ingress
spec:
podSelector: {}
ingress:
- {}
policyTypes:
- Ingress
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-egress
spec:
podSelector: {}
policyTypes:
- Egress
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all-egress
spec:
podSelector: {}
egress:
- {}
policyTypes:
- Egress
你可以为名字空间创建“默认”策略,以通过在该名字空间中创建以下 NetworkPolicy 来阻止所有入站和出站流量
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-all
spec:
podSelector: {} # 应用此策略的Pod的选择器,此处为空表示选择所有的Pod
policyTypes:
- Ingress
- Egress
- 针对某个端口范围
特性状态: Kubernetes v1.25 [stable]
在编写 NetworkPolicy 时,你可以针对一个端口范围而不是某个固定端口。这一目的可以通过使用 endPort 字段来实现,如下例所示:
使用此字段时存在以下限制:
endPort字段必须等于��或者大于port字段的值- 只有在定义了
port时才能定义endPort - 两个字段的设置值都只能是数字
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: multi-port-egress
namespace: default
spec:
podSelector:
matchLabels:
role: db
policyTypes:
- Egress
egress:
- to:
- ipBlock:
cidr: 10.244.0.0/16
ports:
- protocol: TCP
port: 70
endPort: 90
- 生产使用场景
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: access-nginx
spec:
podSelector:
matchLabels:
app: nginx
ingress:
- from:
- podSelector:
matchLabels:
access: "true"
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: web-deny-all
spec:
podSelector:
matchLabels:
app: web
env: prod
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny
namespace: default
spec:
podSelector: {}
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: web-allow-prod
spec:
podSelector:
matchLabels:
app: web
ingress:
- from:
- namespaceSelector:
matchLabels:
purpose: production
注意
-
集群的入站和出站机制通常需要重写数据包的源
IP或目标IP。在发生这种情况时,不确定在NetworkPolicy处理之前还是之后发生,并且对于网络插件、云提供商、Service实现等的不同组合,其行为可能会有所不同- 入站流量而言,这意味着在某些情况下,你可以根据实际的原始源
IP过滤传入的数据包,而在其他情况下,NetworkPolicy所作用的源IP则可能是LoadBalancer或Pod的节点等 - 于出站流量而言,这意味着从
Pod到被重写为集群外部IP的Service IP的连接可能会或可能不会受到基于ipBlock的策略的约束
- 入站流量而言,这意味着在某些情况下,你可以根据实际的原始源
-
通过网络策略(至少目前)无法完成的工作
- 制集群内部流量经过某公用网关(这种场景最好通过服务网格或其他代理来实现);
- 与
TLS相关的场景(考虑使用服务网格或者Ingress控制器); - 特定于节点的策略(你可以使用
CIDR来表达这一需求不过你无法使用节点在Kubernetes中的其他标识信息来辩识目标节点); - 基于名字来选择服务来选择目标
Pod或名字空间; - 创建或管理由第三方来实际完成的“策略请求”;
- 实现适用于所有名字空间或
Pods的默认策略(某些第三方Kubernetes发行版本或项目可以做到这点); - 高级的策略查询或者可达性相关工具;
- 生成网络安全事件日志的能力(例如,被阻塞或接收的连接请求);
- 显式地拒绝策略的能力(目前,
NetworkPolicy的模型默认采用拒绝操作,其唯一的能力是添加允许策略); - 禁止本地回路或指向宿主的网络流量(
Pod目前无法阻塞localhost访问,它们也无法禁止来自所在节点的访问请求);
临时容器
概念
特性状态:Kubernetes vl.25 [stable]
临时容器:一种特殊的容器,该容器在现有 Pod中临时运行,以便完成用户发起的操作,例如故障排查。你会使用临时容器来检查服务,而不是用它来构建应用程序
特性
临时容器与其他容器的不同之处在于,它们缺少对资源或执行的保证,并且永远不会自动重启,因此不适用于构建应用程序。临时容器使用与常规容器相同的 ContainerSpec 节来描述,但许多字段是不兼容和不允许的
- 临时容器没有端口配置,因此像
ports,livenessProbe,readinessProbe这样的字段是不允许的。 Pod资源分配是不可变的,因此resources配置是不允许的。
临时容器是使用 API 中的一种特殊的 ephemeralcontainers 处理器进行�创建的,而不是直接添加到 pod.spec段,因此无法使用 kubectl edit来添加一个临时容器。与常规容器一样,将临时容器添加到 Pod 后,将不能更改或删除临容器
增加一个临时容器
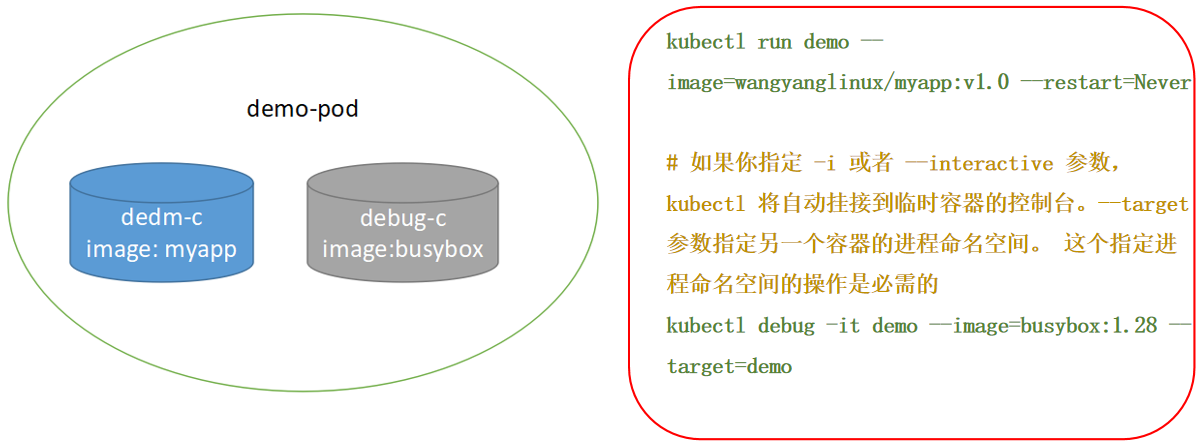
通过 POD 副本调试
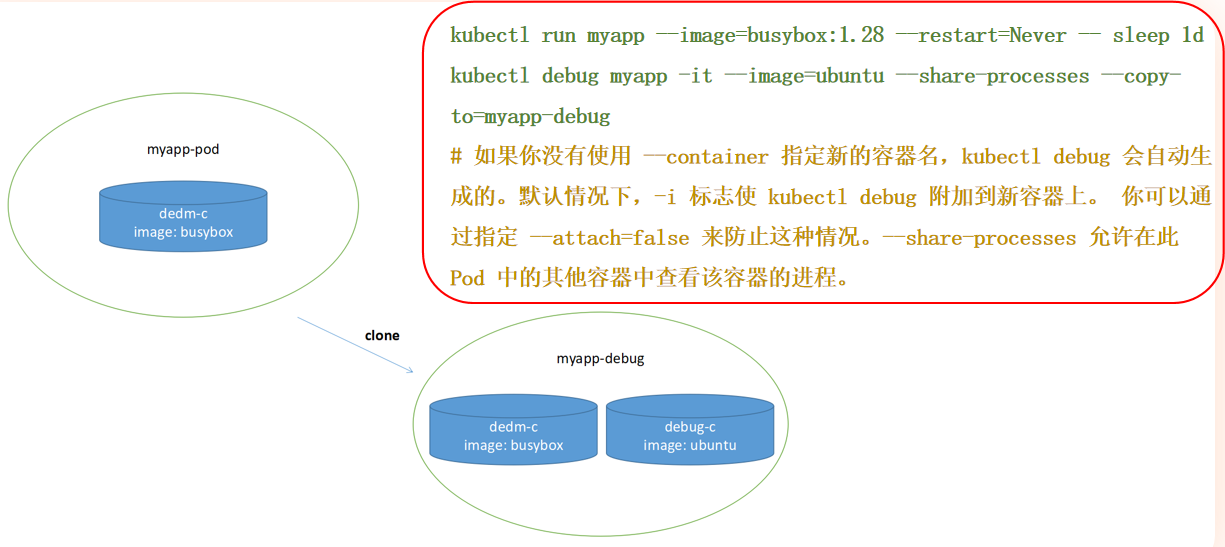
在改变 POD 命令时创建 POD 副本
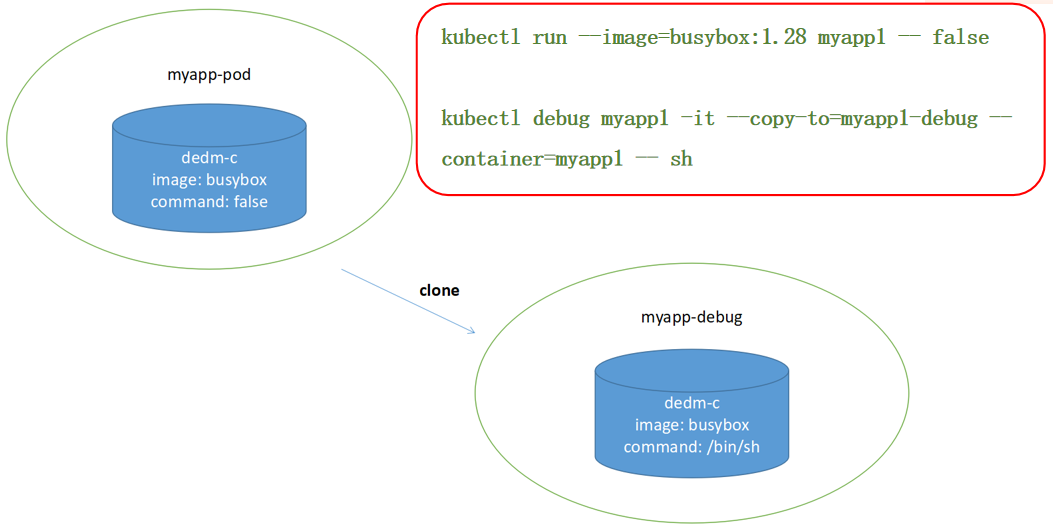
在更改镜像时拷贝 POD
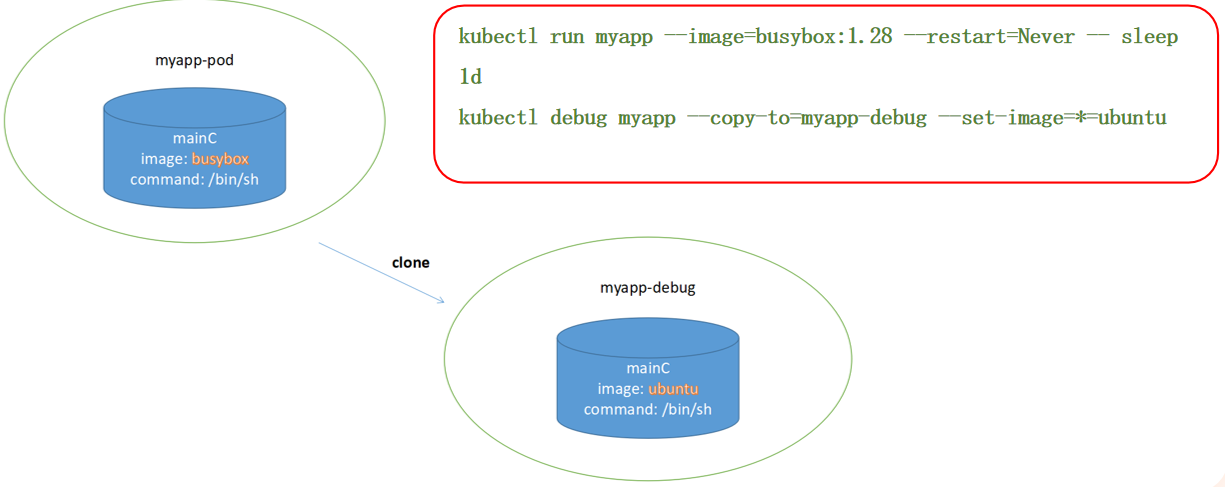
在同一个节点上创建 POD 进行调试
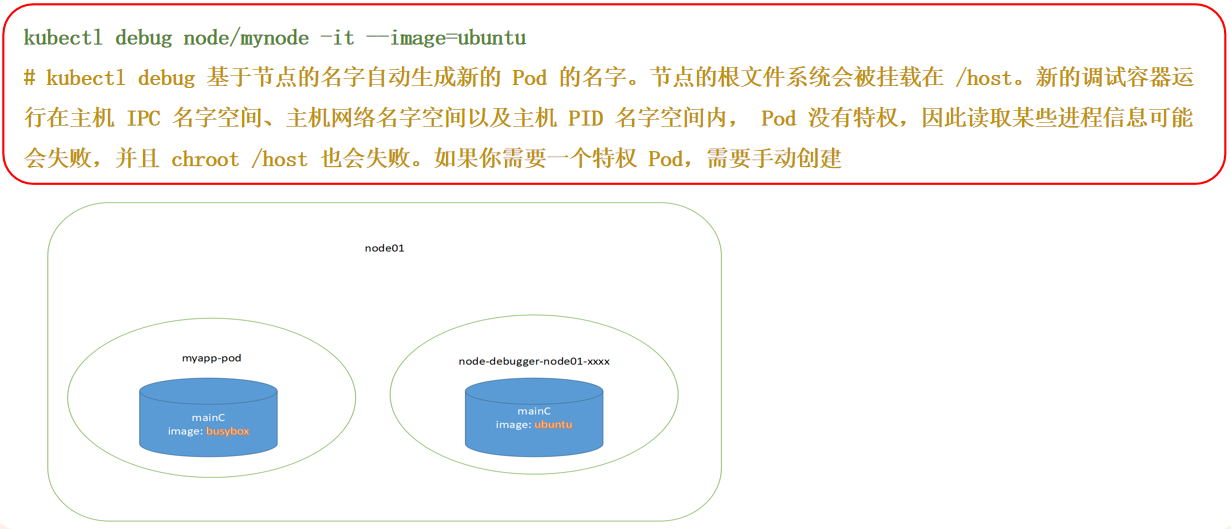
端口转发
基本要求
Kubernetes 服务器版本必须不低于版本 vl.10
用法
$ kubectl port-forward <pod_name> <forward_port> namespace <namespace>--address <IP默认: 127.0.0.1>
$ kubect1 port-forward myapp-6c68ff56c9-d7149 28015:80
$ kubect1 port-forward pods/myapp-6c68ff56c9-d7149 28015:80
$ kubectl port-forward deployment/myapp 28015:80
$ kubectl port-forward replicaset/myapp-75f59d57f4 28015:80
$ kubectl port-forward service/myapp 28015:80
# kubectl工具会找到一个未被使用的本地端口号(避免使用低段位的端口号,因为他们可能会被其他应用程序使用
$ kubectl port-forward deployment/myapp :80
#默认情况下,端口监听本地回环接口,修改地址为0.0.0.0,开启远程访问
$ kubectl port-forward deployment/myapp :80 --address 0.0. 0.0
kubectl port-forward 仅实现了 TCP 端口支持。
审计功能
起因
平台的企业级需求中,多多�少少都会包含审计相关的功能存在,能够在事后确认操作人和错误的原因,以此在后续的工作中避免此类的事件存在。如果想做到此样的功能,应该如何操作呢?
- 计日志(
AuditLogs):Kubernetes提供了审计功能,可以记录对集群资源的操作历史。你可以配置Kubernetes的审计日志功能,使其记录对Deployment、Pod、Service等资源的创建、更新、删除等操作。审计日志通常可以配置为输出到文件、发送到远程日志服务器或集成到安全信息和事件管理(SIEM)系统中 kubernetes事件(Events):Kubernetes中的事件系统记录了对集群中各种资源的操作,包括Deployment。你可以使用kubectl get events命令来查看事件历史记录,或者通过Kubernetes API获取事件数据。你还可以设置自定义的事件记录器,将事件数据输出到日志文件或其他存储介质中- 自定义脚本:你可以编写自定义脚本或控制器来监控
Deployment资源的变化,并将变化记录到日志文件或数据库中。例如,你可以编写一个Python脚本,使用Kubernetes客户端库监听Deployment资源的变化并记录到文件中 - 第三方审计解决方案:一些第三方审计解决方案,如
Aqua Security、Sysdig Secure 等,提供了针对Kubernetes集群的全面审计和安全监控功能,包括记录资源的修改历史
基本概念
Kubernetes 审计日志提供了与安全相关的、按时间顺序排列的记录集,记录每个用户、使用 Kubernetes API 的应用以及控制面自身引发的活动。
审计记录最初产生于 kube-apiserver 内部。每个请求在不同执行阶段都会生成审计事件;这些审计事件会根据特定策略 被预处理并写入后端。策略确定要记录的内容和用来存储记录的后端。当前的后端支持日志文件和 webhook。
几个阶段
| 阶段 | 描述 |
|---|---|
| RequestReceived | 此阶段对应审计处理器接收到请求后,并且在委托给其余处理器之前生成的事件 |
| ResponseStarted | 在响应消息的头部发送后,响应消息体发送前生成的事件。只有长时间运行的请求(例如 watch)才会生成这个阶段 |
| ResponseComplete | 当响应消息体完成并且没有更多数据需要传输的时候 |
| Panic | 当 panic 发生时生成 |
日志级别
| 审计日志 | 描述 |
|---|---|
| None | 符合这条规则的日志将不会记录 |
| Metadata | 记录请求的元数据(请求的用户、时间戳、资源、动词等等),但是不记录请求或者响应的消息体 |
| Request | 记录事件的元数据和请求的消息体,但是不记录响应的消息体。这不适用于非资源类型的请求 |
| RequestResponse | 记录事件的元数据,请求和响应的消息体。这不适用于非资源类型的请求 |
安全参数
节点的名字空间共享
apiVersion: v1
kind: Pod
metadata:
name: hostnetwork-pod
spec:
hostNetwork: true
containers:
- name: myapp-container
image: wangyanglinux/myapp:v1.0
ports:
- containerPort: 80
apiVersion: v1
kind: Pod
metadata:
name: pod-with-hostport
spec:
containers:
- name: myapp-container
image: wangyanglinux/myapp:v1.0
ports:
- containerPort: 80
hostPort: 8080
apiVersion: v1
kind: Pod
metadata:
name: hostpid-hostipc-pod
spec:
hostPID: true
hostIPC: true
containers:
- name: myapp-container
image: wangyanglinux/myapp:v1.0
节点的安全上下文
- 指定容器中运行进程的用户(用户
ID) - 阻止容器使用
root用户运行(容器的默认运行用户通常在其镜像中指定,所以可能需要阻止容器以root用户运行) - 使用特权模式运行容器,使其对宿主节点的内核具有完全的访问权限
- 与以上相反,通过添加或禁用内核功能,配置细粒度的内核访问权限
- 设置
SELinux选项,加强对容器的限制 - 阻止进程写入容器的根文件系统
节点的名字空间共享
apiVersion: v1
kind: Pod
metadata:
name: user-id-pod
spec:
containers:
- name: alpine-container
image: alpine
command: ["/bin/sleep", "9999"]
securityContext:
runAsUser: 405
apiVersion: v1
kind: Pod
metadata:
name: non-root-user-pod-false
spec:
containers:
- name: myapp-container
image: wangyanglinux/myapp:v1.0
securityContext:
runAsNonRoot: true
apiVersion: v1
---
kind: Pod1
metadata:
name: non-root-user-pod-true
spec:
containers:
- name: myapp-container
image: wangyanglinux/myapp:v1.0-nonroot
securityContext:
runAsNonRoot: true
runAsUser: 102
在某些情况下,即使容器镜像中使用的是普通用户,也可能需要明确指定 runAsUser 。这可能是由于容器镜像中的用户与宿主机上的用户 UID 不匹配导致的。在这种情况下,即使容器中的用户是普通用户, Kubernetes 也可能会认为其是 root 用户,因为它的 UID 与宿主机上的 root 用户的 UID 匹配。因此,即使容器中的用户是普通用户,也建议明确指定 runAsUser ,以确保容器以正确的用户身份运行。
apiVersion: v1
kind: Pod
metadata:
name: privileged-pod
spec:
containers:
- name: privileged-container
image: wangyanglinux/myapp:v1.0
securityContext:
privileged: true
apiVersion: v1
kind: Pod
metadata:
name: sys-time-pod
spec:
containers:
- name: sys-time-container
image: wangyanglinux/myapp:v1.0
securityContext:
capabilities:
add: ["NET_ADMIN"]
apiVersion: v1
kind: Pod
metadata:
name: disable-chown-pod
spec:
containers:
- name: nginx-container
image: wangyanglinux/myapp:v1.0
securityContext:
capabilities:
drop:
- CHOWN
apiVersion: v1
kind: Pod
metadata:
name: pod-with-readonly-filesystem
spec:
containers:
- name: main
image: wangyanglinux/tools:alpine
command: ["/bin/sleep", "9999"]
securityContext:
readOnlyRootFilesystem: true
volumeMounts:
- name: my-volume
mountPath: /volume
readOnly: false
volumes:
- name: my-volume
emptyDir:
apiVersion: v1
kind: Pod
metadata:
name: pod-with-shared-volume-fsgroup
spec:
securityContext:
fsGroup: 555
supplementalGroups: [666, 777]
containers:
- name: first
image: wangyanglinux/tools:alpine
command: ["/bin/sleep", '9999']
securityContext:
runAsUser: 1111
volumeMounts:
- name: shared-volume
mountPath: /volume
readOnly: false
- name: second
image: wangyanglinux/tools:alpine
command: ["/bin/sleep", '9999']
securityContext:
runAsUser: 2222
volumeMounts:
- name: shared-volume
mountPath: /volume
readOnly: false
volumes:
- name: shared-volume
emptyDir:
PodSecurityAdmission
从 Kubernetes vl.21 开始,Pod Security Policy 将被弃用,并将在 v1.25 中删除,Kubernetes 在 1.22 版本引l入了 Pod Security Admission 作为其替代者
Pod Security Admission机制在易用性和灵活性上都有了很大提升,从使用角度有以下四点显著不同:- 以在集群中默认开启,只要不设置约束条件就不会触发对
pod的校验 - 在命名空间级别生效,可以为不同命名空间通过添加标签的方式设置不同的安全限制
- 据实践预设了三种安全等级,不需要由用户单独去设置每一项安全条件
- 以在集群中默认开启,只要不设置约束条件就不会触发对
PodSecurity Standards
为了广泛的覆盖安全应用场景,Pod Security Standards 渐进式的定义了三种不同的 Pod 安全标准策略:
| 策略 | 描述 |
|---|---|
| Privileged | 不受限制的策略,提供最大可能范围的权限许可。此策略允许已知的特权提升 |
| Baseline | 限制性最弱的策略,禁止已知的策略提升。允许使用默认的(规定最少)Pod配置 |
| Restricted | 限制性非常强的策略,遵循当前的保护 Pod 的最佳实践 |
PodSecurity adminssion
在 Kubernetes 集群中开启了 podSecurity admission 后,就可以通过给 namespace 设置 label 的方式来实施 Pod Security Standards。其中有三种设定模式可选用:
| 模式 | 描述 |
|---|---|
| enforce | 违反安全标准策略的 Pod 将被拒绝 |
| audit | 违反安全标准策略触发向审计日志中记录的事件添加审计注释,但其他行为被允许 |
| warn | 违反安全标准策略将触发面向用户的警��告,但其他行为被允许 |
label 设置模板解释
- 设定模式及安全标准策略等级
pod-security.kubernetes.io/<MoDE>: <LEVEL>MODE必须是enforce,audit或warn其中之一。LEVEL必须是privileged,baseline或restricted其中之一
- 此选项是非必填的,用来锁定使用哪个版本的的安全标准
pod-security. kubernetes.io/<MODE>-version: <VERSION>MODE必须是enforce,audit或warn其中之一。VERSION必须是一个有效的kubernetesminor version(例如vl.23),或者latest
Baseline
Baseline 策略目标是应用于常见的容器化应用,禁止已知的特权提升,在官方的介绍中此策略针对的是应用运维人员和非关键性应用开发人员,在该策略中包括:必须禁止共享宿主命名空间、禁止容器特权、限制Linux 能力、禁止 hostPath 卷、限制宿主机端口、设定 AppArmor、SElinux、Seccomp、Sysctls 等
- 违反
Baseline策略存在的风险:- 权容器可以看到宿主机设备
- 挂载
procfs后可以看到宿主机进程,打破进程隔离 - 以打�破网络隔离
- 挂载运行时
socket后可以不受限制的与运行时通信
Restricted
Restricted 策略目标是实施当前保护 Pod 的最佳实践,在官方介绍中此策略主要针对运维人员和安全性很重要的应用开发人员,以及不太被信任的用户。该策略包含所有的 baseline 策略的内容,额外增加:限制可以通过 PersistentVolumes 定义的非核心卷类型、禁止(通过 SetUID 或 SetGID 文件模式)获得特权提升、必须要求容器以非 root 用户运行、Containers 不可以将 runAsUser 设置为O、容器组必须弃用 ALL capabilities 并且只允许添加 NET_BIND_SERVICE 能力
Restricted 策略进一步的限制在容器内获取 root 权限,linux 内核功能。例如针对 kubernetes 网络的中间人攻击需要拥有 Linux 系统的 CAP_NET_RAW 权限来发送 ARP 包。
局限性
podSecurity admission只是对pod进行安全标准的检查,不支持对pod进行修改,不能为pod设置默认的安全配置。podSecurity admission只支持官方定义的三种安全标准策略,不支持灵活的自定义安全标准策略。这使得不能完全将PSP规则迁移到podSecurity admission,需要进行具体的安全规则考量。
资源限制
概念
Kubernetes 对资源的限制实际上是通过 CGROUP 来控制的,CGROUP 是容器的一组用来控制内核如果运行进程的相关属性集合。针对内存、CPU、和各种设备都有对应的 CGROUP
默认情况下,Pod 运行没有 CPU 和内存的限额。这意味着系统中任何 Pod 将能够执行该节点所有的运算资源,消耗足够多的 CPU 和内存。一般会针对某些应用的 Pod 资源进行资源限制,这个资源限制是通过 resources 的 requests 和 limits 来实现
特性
- 调度器在调度时并不关注各类资源在当前时刻的实际使用量,而只关心节点上部署的所有
Pod的资源申请量之和 - 在容器内看到的始终是节点的内存,而不是容器本身的内存
- 容器内看到的始终是节点所有的
CPU核,而不是仅仅只是容器可用的
$ kubectl autoscale deployment my-deploymentcpu-percent=50 --min=2 --max=10
$ kubectl run -i --tty work --image=busybox /bin/sh
# 测试
$ while true; do wget -q -0- http://php-apache.default. svc.cluster.local; done
QoS 等级
- BestEffort(优先级最低)
- 会分配给那些没有为任何容器设置
requests和limits 的Pod - 最坏情况下,它们可能分配不到任何资源。同时,在需要为其它
Pod释放资源时,这些容器会被第一批杀死 - 为没有设置资源限制,所以资源在足够使用时,这些容器可以使用任意多的资源量级
- 会分配给那些没有为任何容器设置
- Burstable
Burstable QoS等级介于BestEffort和Guaranteed之间,只要不归属于BestEffort和Guaranteed均归于此等级
- Guaranteed(优先级最高)
- 会分配给那些所有资源
request和limits相等的Pod - 如果容器的资源
requests没有显式设置,默认与limits相同
- 会分配给那些所有资源
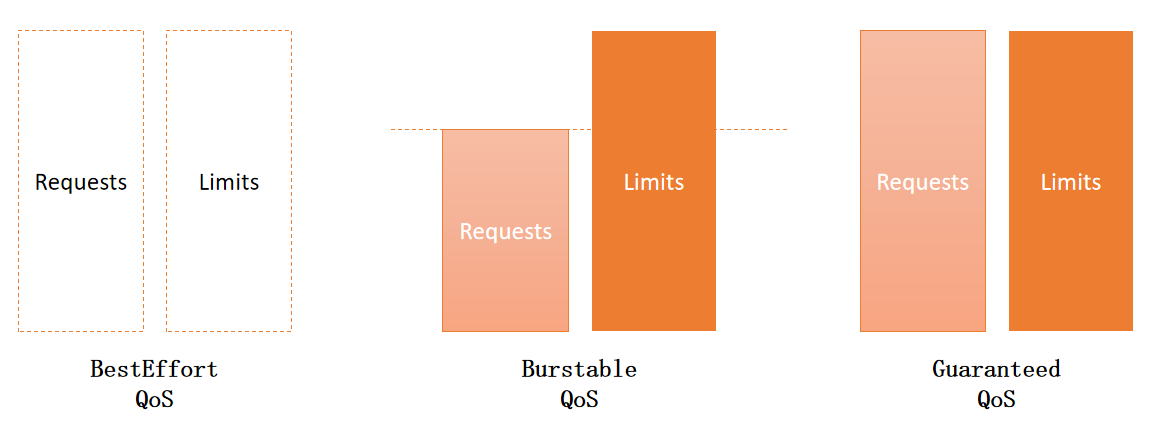
单容器 POD
| CPU requests vs limits | 内存的 requests vs limits | 容器的QoS等级 |
|---|---|---|
| 未设置 | 未设置 | BestEffort |
| 未设置 | Requests < Limits | BestEffort |
| 未设置 | Requests = Limits | Burstable |
| Requests < Limits | Requests = Limits | Burstable |
| Requests < Limits | Requests < Limits | Burstable |
| Requests < Limits | Requests = Limits | Burstable |
| Requests = Limits | Requests = Limits | Guaranteed |
多容器 POD
| 容器 1 的 QoS 等级 | 容器 2 的QoS 等级 | POD的QoS等级 |
|---|---|---|
| BestEffort | BestEffort | BestEffort |
| BestEffort | Burstable | Burstable |
| BestEffort | Guaranteed | Burstable |
| Burstable | Burstable | Burstable |
| Burstable | Guaranteed | Burstable |
| Guaranteed | Guaranteed | Guaranteed |
limitRange 概念
通过创建一个 LimitRange 资源来避免必须配置每个容器的资源限制。LimitRange 资源不仅允许用户(为每个命名空间)指定能给容器配置的每种资源的最小和最大限额,还支持在没有显示指定资源 request 时为容器设置默认值
ResourceQuota 概念
LimitRange 只应用于单独的 Pod,而集群需要一种手段可以限制命名空间中的可用资源总量,这个就是 ResourceQuota
ResourceQuota 限制了一个命名空间中 pod 和 PVC 存储最多可以使用的资源总量。同时也可以限制用户允许在该命名空间中创建 pod、PVC 以及其它 API 对象的数量
Drain
Drain & Cordon
Cordon
$ kubectl cordon NODE [options]
设置节点不可调度,仅仅是节点不可调度而已,已存在的 pod 不会驱逐,新的 pod 不会被调度到该节点上
$ kubectl uncordon NODE [options]
Cordon
$ kubectl drain NODE [options]
# --grace-period 指定宽限期
# --ignore-daemonsets=true 跳过 ds 控制器
$ kubectl drain NODE --ignore-daemonsets=true --grace-period=900
一且执行了 kubectl drain〈node-name>,Kubernetes 将开始迁移节点上的工作负载,直到所有的 Pod 都已经被成功调度到其他节点为止。在此过程中,新的 Pod 将不会被调度到正在排空的节点上,以确保在维护期间不会有新的负载进入。
排空过程中,Kubernetes 会等待节点上的 Pod 自然地完成它们的任务,并将其调度到其他节点。对于无法重新调度的 Pod,可以使用 --force 标志来强制删除它们。完成排空后,节点将处于无工作负载的状态,可以安全地进行维护操作。完成维护后,可以使用 kubectl uncordon〈node-name〉 命令来重新启用节点,使其恢复正常的调度功能。
特别说明
kubectl drain 操作会将相应节点上的旧 Pod 删除,并在可调度节点上面起一个对应的 Pod。当旧 Pod 没有被正常删除的情况下,新 Pod 不会起来。例如:旧 Pod 一直处于 Terminating 状态。
对应的解决方式是通过重启相应节点的 kubelet,或者强制删除该 Pod。
# 重启发生 Terminating 节点的 kubelet
systemctl restart kubelet
#强制删除 Terminating 状态的Pod
kubectl delete pod <PodName> --namespace=<Namespace> -—forcee —-grace-period=0
Taints 更适合在维护前准备节点,阻止新的 Pod 被调度到节点上;而 Drain 更适合在维护期间确保节点上的所有工作负载被安全地迁移。
自定义 CRD
概念
随着 Kubernetes 生态系统的持续发展,越来越多高层次的对象将会不断涌现。比起目前使用的对象,新对象将更加专业化。有了它们,开发者将不再需要逐一进行 Deployment、Service、configMap 等步骤,而是创建并管理一些用于表述整个应用程序或者软件服务的对象。我们能使用自定义控件观察高阶对象,并在这些高阶对象的基础上创建底层对象。例如,你想在 Kubernetes 集群中运行一个 messaging 代理,只需要创建一个队列资源实例,而自定义队列控件将自动完成所需的 Secret、Deployment 和 Service。目前,Kubernetes 已经提供了类似的自定义资源添加方式。
CustomResourceDefinitions,开发者只需向 Kubernetes API 服务器提交 CRD 对象,即可定义新的资源类型成功提交 CRD 之后,我们就能够通过 API 服务器提交 JSON 清单或者 YAML 清单的方式创建自定义资源,以及其他 Kubernetes 资源实例
注意:在 Kubernetes 1.7 之前的版本中,需要通过 ThirdPartyResource 对象的方式定义自定义资源,ThirdPartyResource 于 CRD 十分相似,但是在 Kubernetes 1.8 中被 CRD 取代
开发者可以通过创建 CRD 来创建新的对象类型。但是,如果创建的对象无法在集群中解决实际问题,那么它就是一个无效特性。通常,CRD 与所有 Kubernetes 核心资源都有一个关联的控制器(一个基于自定义对象有效实现目标的组件)
创建流程
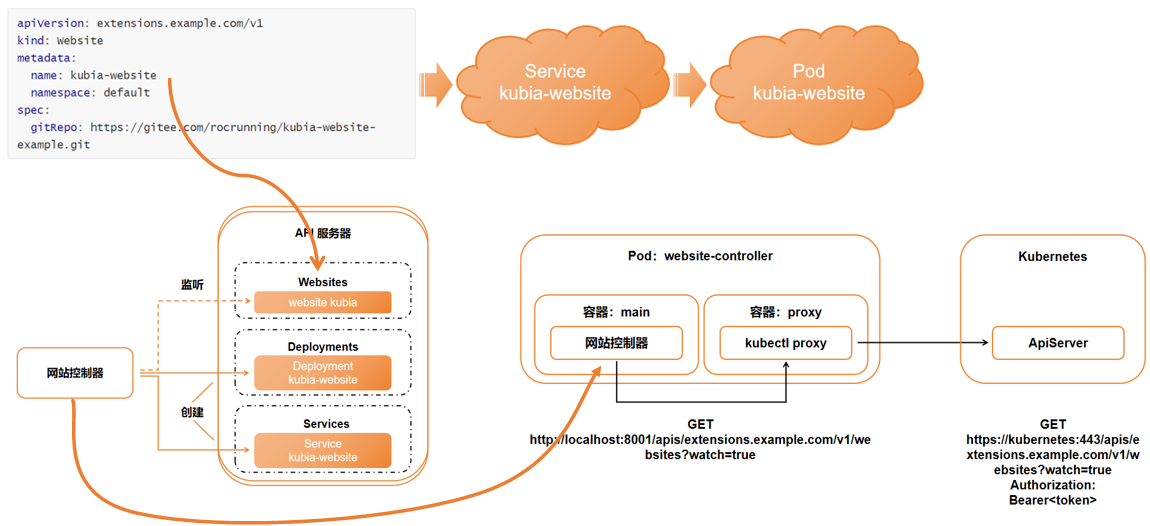
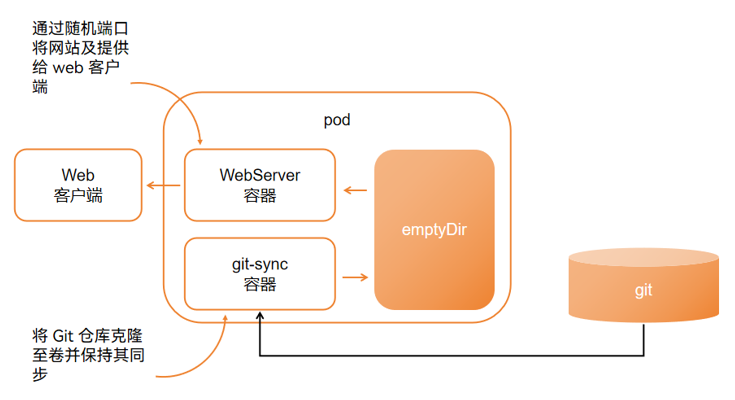
CRD安装
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: websites.extensions.example.com
spec:
group: extensions.example.com
versions:
- name: v1
served: true
storage: true
schema:
openAPIV3Schema:
type: object
properties:
spec:
type: object
properties:
gitRepo:
type: string
required:
- spec
scope: Namespaced
names:
plural: websites
singular: website
kind: Website
# [root@k8s-master01 deployment]# cat demo-website-example.yaml
apiVersion: extensions.example.com/v1
kind: Website
metadata:
name: xxhf
namespace: default
spec:
gitRepo: https://gitee.com/rocrunning/kubia-website-example.git
package main
import (
"fmt"
"net/http"
"encoding/json"
"io"
"log"
"website-controller/v1"
"io/ioutil"
"strings"
)
func main() {
log.Println("website-controller started.")
for {
resp, err :=
http.Get("http://localhost:8001/apis/extensions.example.com/v1/websites?
watch=true")
if err != nil {
panic(err)
}
defer resp.Body.Close()
decoder := json.NewDecoder(resp.Body)
for {
var event v1.WebsiteWatchEvent
if err := decoder.Decode(&event); err == io.EOF {
break
} else if err != nil {
log.Fatal(err)
}
log.Printf("Received watch event: %s: %s: %s\n", event.Type,
event.Object.Metadata.Name, event.Object.Spec.GitRepo)
if event.Type == "ADDED" {
createWebsite(event.Object)
} else if event.Type == "DELETED" {
deleteWebsite(event.Object)
}
}
}
}
func createWebsite(website v1.Website) {
createResource(website, "api/v1", "services", "service-template.json")
createResource(website, "apis/apps/v1", "deployments", "deployment-
template.json")
}
func deleteWebsite(website v1.Website) {
deleteResource(website, "api/v1", "services", getName(website));
deleteResource(website, "apis/apps/v1", "deployments", getName(website));
}
func createResource(webserver v1.Website, apiGroup string, kind string, filename
string) {
log.Printf("Creating %s with name %s in namespace %s", kind,
getName(webserver), webserver.Metadata.Namespace)
templateBytes, err := ioutil.ReadFile(filename)
if err != nil {
log.Fatal(err)
}
template := strings.Replace(string(templateBytes), "[NAME]",
getName(webserver), -1)
template = strings.Replace(template, "[GIT-REPO]", webserver.Spec.GitRepo,
-1)
resp, err :=
http.Post(fmt.Sprintf("http://localhost:8001/%s/namespaces/%s/%s/", apiGroup,
webserver.Metadata.Namespace, kind), "application/json",
strings.NewReader(template))
if err != nil {
log.Fatal(err)
}
log.Println("response Status:", resp.Status)
}
func deleteResource(webserver v1.Website, apiGroup string, kind string, name
string) {
log.Printf("Deleting %s with name %s in namespace %s", kind, name,
webserver.Metadata.Namespace)
req, err := http.NewRequest(http.MethodDelete,
fmt.Sprintf("http://localhost:8001/%s/namespaces/%s/%s/%s", apiGroup,
webserver.Metadata.Namespace, kind, name), nil)
if err != nil {
log.Fatal(err)
return
}
resp, err := http.DefaultClient.Do(req)
if err != nil {
log.Fatal(err)
return
}
log.Println("response Status:", resp.Status)
}
func getName(website v1.Website) string {
return website.Metadata.Name + "-website";
}
// [root@k8s-master01 build]# cat deployment-template.json
{
"apiVersion": "apps/v1",
"kind": "Deployment",
"metadata": {
"name": "[NAME]",
"labels": {
"webserver": "[NAME]"
}
},
"spec": {
"replicas": 1,
"selector": {
"matchLabels": {
"webserver": "[NAME]"
}
},
"template": {
"metadata": {
"name": "[NAME]",
"labels": {
"webserver": "[NAME]"
}
},
"spec": {
"containers": [
{
"image": "wangyanglinux/tools:nginxCRD",
"name": "main",
"volumeMounts": [
{
"name": "html",
"mountPath": "/usr/share/nginx/html",
"readOnly": true
}
],
"ports": [
{
"containerPort": 80,
"protocol": "TCP"
}
]
},
{
"image": "wangyanglinux/tools:gitsync",
"name": "git-sync",
"env": [
{
"name": "GIT_SYNC_REPO",
"value": "[GIT-REPO]"
},
{
"name": "GIT_SYNC_DEST",
"value": "/gitrepo"
},
{
"name": "GIT_SYNC_BRANCH",
"value": "master"
},
{
"name": "GIT_SYNC_REV",
"value": "FETCH_HEAD"
},
{
"name": "GIT_SYNC_WAIT",
"value": "10"
}
],
"volumeMounts": [
{
"name": "html",
"mountPath": "/gitrepo"
}
]
}
],
"volumes": [
{
"name": "html",
"emptyDir": {}
}
]
}
}
}
}
// [root@k8s-master01 build]# cat service-template.json
{
"apiVersion": "v1",
"kind": "Service",
"metadata": {
"labels": {
"webserver": "[NAME]"
},
"name": "[NAME]"
},
"spec": {
"type": "NodePort",
"ports": [
{
"port": 80,
"protocol": "TCP",
"targetPort": 80
}
],
"selector": {
"webserver": "[NAME]"
}
}
}
# [root@k8s-master01 build]# cat Dockerfile
FROM scratch
MAINTAINER wangyanglinux@163.com
ADD website-controller /
ADD deployment-template.json /
ADD service-template.json /
CMD ["/website-controller"]
部署 website
# [root@k8s-master01 deployment]# cat rbac.yaml
apiVersion: v1
kind: Namespace
metadata:
name: website
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: website-controller
namespace: website
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: website-controller
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: website-controller
namespace: website
# [root@k8s-master01 deployment]# cat website-controller-deployment-example.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: website-controller
namespace: website
spec:
replicas: 1
selector:
matchLabels:
app: website-controller
template:
metadata:
labels:
app: website-controller
spec:
containers:
- image: wangyanglinux/tools:website-controller
name: main
- image: wangyanglinux/tools:kubectl-proxy
name: proxy
serviceAccount: website-controller
serviceAccountName: website-controller
BACKUP
ETCD 数据库备份还原
$ docker cp $(docker ps grep -v etcd-mirror | grep -w etcd | awk '{print$1}'):/usr/local/bin/etcdctl /usr/bin/
$ ETCDCTL_API=3 etcdct1 --endpoints="https: //127.0.0.1:2379" --cert="/etc/kubernetes/pki/etcd/server.crt" --key="/etc/kubernetes/pki/etcd/server.key" --cacert="/etc/kubernetes/pki/etcd/ca.crt" snapshot save /backup_$(date +%Y%m%d)/snap-$(date+%Y%m%d%H%M) . db
$ mv /var/lib/etcd/ /var/lib/etcd-back && mkdir /var/lib/etcd && chmodd 700 /var/lib/etcd
# 还原数据时需保证 apiServer 和 etcd 处于关闭状态,最简单的方式就是 mv manifests manifests_back
$ ETCDCTL_API=3 etcdct1 --data-dir=/var/1ib/etcd --endpoints="https://127.0.0.1:2379" --cert="/etc/kubernetes/pki/etcd/server.crt" --key="/etc/kubernetes/pki/etcd/server.key" --cacert="/etc/kubernetes/pki/etcd/ca.crt" snapshot restore /backup_20220108/snap-202201081337.db
ETCD BACKUP
一、单节点 etcd 数据备份和恢复
1、kubeadm 安装方式
a、拷贝 etcdctl 至 master 节点
$ docker cp $(docker ps | grep -v etcd-mirror | grep -w etcd | awk '{print $1}'):/usr/local/bin/etcdctl /usr/bin/
b、基于 ETCD v3 接口实现数据备份
$ ETCDCTL_API=3 etcdctl --endpoints="https://127.0.0.1:2379" --cert="/etc/kubernetes/pki/etcd/server.crt" --key="/etc/kubernetes/pki/etcd/server.key" --cacert="/etc/kubernetes/pki/etcd/ca.crt" snapshot save snap-$(date +%Y%m%d%H%M).db
c、恢复 etcd 数据
$ mv manifests manifests.bak
停止 etcd 和 apiServer
$ ETCDCTL_API=3 etcdctl --endpoints="https://127.0.0.1:2379" --cert="/etc/kubernetes/pki/etcd/server.crt" --key="/etc/kubernetes/pki/etcd/server.key" --cacert="/etc/kubernetes/pki/etcd/ca.crt" snapshot restore snap-202201081337.db
2、二进制集群 安装方式
a、备份 etcd
$ yum install -y etcd
$ ETCDCTL_API=3 etcdctl snapshot save snap.20240422.db --cacert=/etc/etcd/ssl/ca.pem --cert=/etc/etcd/ssl/etcd.pem --key=/etc/etcd/ssl/etcd-key.pem --endpoints="https://192.168.66.11:2379"
b、etcd 数据库还原
$ systemctl stop kube-apiserver
$ systemctl stop etcd
$ mv /var/lib/etcd/default.etcd /var/lib/etcd/default.etcd.bak
# 查看数据库路径
# systemctl cat etcd.service
$ ETCDCTL_API=3 etcdctl snapshot restore /data/backup/etcd-snapshot-previous.db --data-dir=/var/lib/etcd/default.etcd
$ chown -R etcd:etcd /var/lib/etcd
$ systemctl start kube-apiserver
$ systemctl start etcd.service
二、高可用 Etcd 数据库的还原
1、kubeadm 安装方式
a、可以在多个 master 节点上执行备份操作
$ ETCDCTL_API=3 etcdctl --endpoints="https://127.0.0.1:2379" --cert="/etc/kubernetes/pki/etcd/server.crt" --key="/etc/kubernetes/pki/etcd/server.key" --cacert="/etc/kubernetes/pki/etcd/ca.crt" snapshot save /snap-$(date +%Y%m%d%H%M).db
b、停止 apiServer 和 etcd 后,执行恢复步骤
在 master1 上执行
ETCDCTL_API=3 etcdctl snapshot restore snap-20240422.db \
--endpoints=192.168.66.11:2379 \
--name=master1 \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--initial-advertise-peer-urls=https://192.168.66.11:2380 \
--initial-cluster-token=etcd-cluster-0 \
--initial-cluster=master1=https://192.168.66.11:2380,master2=https://192.168.66.12:2380,master3=https://192.168.66.13:2380 \
--data-dir=/var/lib/etcd
在 master2 上执行
ETCDCTL_API=3 etcdctl snapshot restore snap-20240422.db \
--endpoints=192.168.66.12:2379 \
--name=master2 \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--initial-advertise-peer-urls=https://192.168.66.12:2380 \
--initial-cluster-token=etcd-cluster-0 \
--initial-cluster=master1=https://192.168.66.11:2380,master2=https://192.168.66.12:2380,master3=https://192.168.66.13:2380 \
--data-dir=/var/lib/etcd
在 master3 上执行
ETCDCTL_API=3 etcdctl snapshot restore snap-20240422.db \
--endpoints=192.168.66.13:2379 \
--name=master3 \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--initial-advertise-peer-urls=https://192.168.66.13:2380 \
--initial-cluster-token=etcd-cluster-0 \
--initial-cluster=master1=https://192.168.66.11:2380,master2=https://192.168.66.12:2380,master3=https://192.168.66.13:2380 \
--data-dir=/var/lib/etcd
备注: 1)ETCDCTL_API=3,指定使用 Etcd 的 v3 版本的 API; 2)如果不知道 --name= 则可以用如下命令查看
集群列出成员
ETCDCTL_API=3 etcdctl --endpoints 192.168.66.11:2379,192.168.66.12:2379,192.168.66.13:2379 --cert="/etc/kubernetes/pki/etcd/server.crt" --key="/etc/kubernetes/pki/etcd/server.key" --cacert="/etc/kubernetes/pki/etcd/ca.crt" member list --write-out=table
2、二进制集群 安装方式
a、安装 etcdctl
$ yum install -y etcd
b、备份
$ ETCDCTL_API=3 etcdctl \
snapshot save snap.db \
--endpoints=https://192.168.66.11:2379 \
--cacert=/opt/etcd/ssl/ca.pem \
--cert=/opt/etcd/ssl/server.pem \
--key=/opt/etcd/ssl/server-key.pem
c、恢复
先暂停 kube-apiserver 和 etcd
$ systemctl stop kube-apiserver
$ systemctl stop etcd etcd
$ mv /var/lib/etcd/default.etcd /var/lib/etcd/default.etcd.bak
节点一恢复
ETCDCTL_API=3 etcdctl snapshot restore snap.db \
--name etcd-1 \
--initial-cluster= "etcd-1=https://192.168.66.11:2380,etcd-2=https://192.168.66.12:2380,etcd-3=https:192.168.66.13:2380" \
--initial-advertise-peer-url=https://192.168.66.11:2380 \
--data-dir=/var/lib/etcd/default.etcd
节点二恢复
ETCDCTL_API=3 etcdctl snapshot restore snap.db \
--name etcd-2 \
--initial-cluster= "etcd-1=https://192.168.66.11:2380,etcd-2=https://192.168.66.12:2380,etcd-3=https:192.168.66.13:2380" \
--initial-advertise-peer-url=https://192.168.66.12:2380 \
--data-dir=/var/lib/etcd/default.etcd
节点三恢复
ETCDCTL_API=3 etcdctl snapshot restore snap.db \
--name etcd-3 \
--initial-cluster= "etcd-1=https://192.168.66.11:2380,etcd-2=https://192.168.66.12:2380,etcd-3=https:192.168.66.13:2380" \
--initial-advertise-peer-url=https://192.168.66.13:2380 \
--data-dir=/var/lib/etcd/default.etcd
启动 kube-apiserver 和 etcd
mv /var/lib/etcd/default.etcd.bak /var/lib/etcd/default.etcd
systemctl start kube-apiserver
systemctl start etcd.service
Velero
说明
Velero 是由 GO 语言编写的一款用于灾难恢复和迁移工具,可以安全的备份、恢复和迁移 Kubernetes 集群资源和持久卷。
Velero主要提供以下能力- 备份 ·Kubernetes· 集群资源,并在资源丢失情况下进行还原
- 将集群资源迁移到其他集群
- 将生产集群复制到开发和测试集群
原理
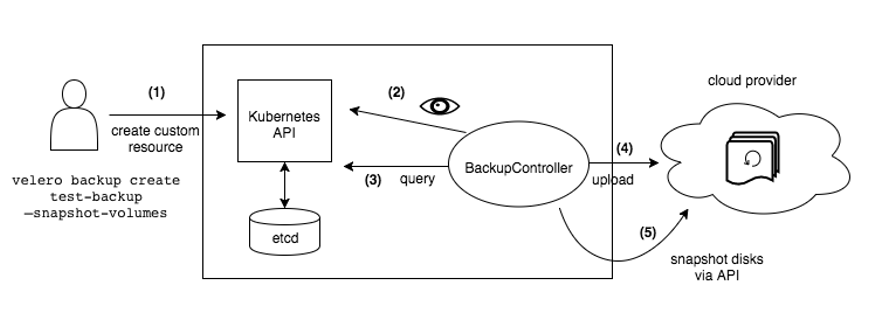
对象存储同步
Velero 将对象存储视为事实来源。它不断检查以确保始终存在正确的备份资源。如果存储桶中有格式正确的备份文件,但 Kubernetes API 中没有对应的备份资源,Velero 会将信息从对象存储同步到Kubernetes 。